
LLMO対策とは?AIに引用される記事の書き方と5つの条件
ChatGPTやAI Overviewsに引用されるためのLLMO対策をコンテンツ設計の観点から解説。AIに選ばれる記事の5条件、CEP/KBF/RTBフレームワーク、Schema.org連携、設計の4ステップまで実務に落とし込みやすい形でまとめました。
- 対象読者: SEO・AI検索対策 / コンテンツ制作 / AI検索最適化に関心がある担当者
- 確認日: 2026年5月14日
- 要点: ChatGPTやAI Overviewsに引用されるためのLLMO対策をコンテンツ設計の観点から解説。AIに選ばれる記事の5条件、CEP/KBF/RTBフレームワーク、Schema.org連携、設計の4ステップまで実務に落とし込みやすい形でまとめました。
Moeko M
コンテンツマネージャー

目次
「ChatGPTに自社サービスを聞いたら、競合ばかり紹介された」——こうした経験はありませんか? ここ1〜2年でChatGPT・Perplexity・Google AI Overviewsを日常的に使うユーザーが急増し、検索結果の上位に表示されるだけでは指名や問い合わせに繋がりにくい時代になりました。
そこで本記事では、AIに引用される記事を作るためのコンテンツ設計を、5つの引用条件とCEP/KBF/RTBフレームワークに整理して解説します。
記事の前半では「なぜ今LLMO対策が必要か」とSEOとの関係を整理し、中盤でAIに引用される記事/されない記事の差を5条件に分解します。後半ではCEP(Category Entry Point)・KBF(Key Buying Factor)・RTB(Reason To Believe)を組み合わせた4ステップの設計プロセスと、Schema.org連携の実装ポイントまで踏み込みます。
読み終える頃には、自社の既存記事のどこをどう書き換えれば「AIから引用される情報源」になれるか、優先順位を立てて判断できるはずです。
技術的なLLMO施策(`llms.txt`の実装ガイドや構造化データ)と組み合わせることで、コンテンツ側の打ち手は効果が最大化します。
LLMO対策が必要な背景:AI検索の台頭とSEOの変化
検索行動の構造変化
ユーザーがGoogleの10本リンクを順に踏む時代から、AIが要約して直接回答する時代に移ったことが、LLMO対策が不可欠になった最大の理由です。
従来のSEOでは「検索結果の1ページ目に表示されること」が最大の目標でした。ユーザーはGoogleで検索し、表示されたリンクから選んでクリックする行動パターンが前提だったためです。
しかしAI検索では、ユーザーの質問に対してAIが直接回答を生成します。その際、AIは学習データやリアルタイム検索で得た情報から「信頼できるソース」を選び、回答に引用します。
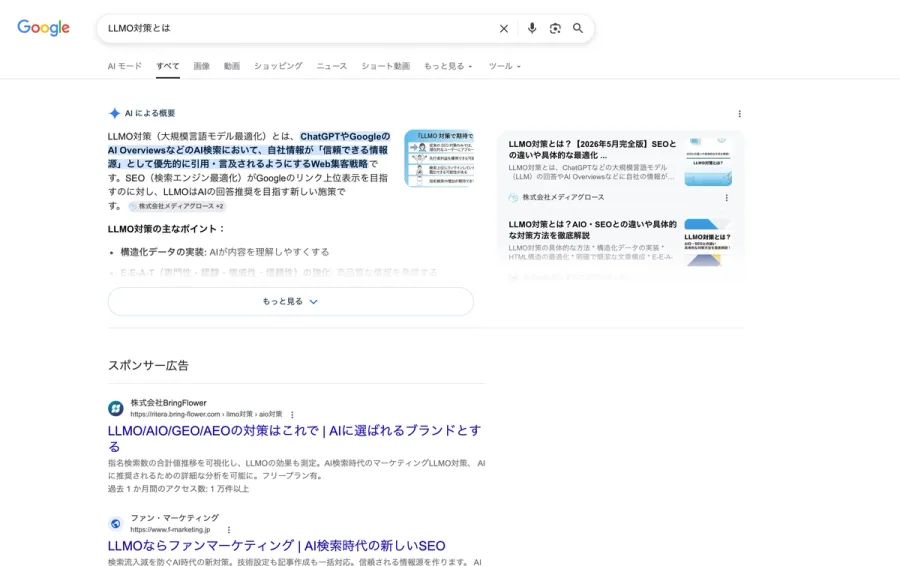
これは「LLMO対策とは」で検索した際のAI回答画面(2026年5月時点)です。複数の外部サイトから引用しながら回答が生成されていることがわかります。
つまり、検索結果に表示されるだけでは不十分で、AIに「引用元」として選ばれる必要があるのです。Google AI Overviewsを含む生成AI時代のWeb最適化全般の考え方は、AIO(AI Optimization)の基礎と海外マーケティング戦略で整理しています。
LLMO対策とSEOの関係
LLMO対策はSEOを否定する施策ではなく、SEOの延長線上にある進化版です。Googleが評価する「E-E-A-T(経験・専門性・権威性・信頼性)」は、AIモデルが引用元を選ぶ基準とも大きく重なります。
ただし決定的な違いもあります。SEOでは「キーワードの網羅性」や「被リンク数」が重視されるのに対し、LLMO対策では「回答としての明確さ」と「独自見解の有無」がより重視されます。AIは曖昧な表現よりも、断定的で根拠のある情報を優先的に引用する傾向があります。
AIが「引用したくなる」コンテンツの5つの条件
条件1:明確な見出し構造とFAQ形式
AIモデルがWebコンテンツを処理する際、最初に参照するのが見出し(H1〜H3)の階層構造です。見出しが論理的に整理されている記事は、AIにとって情報の抽出が容易で引用されやすくなります。
特に効果的なのがFAQ形式です。「LLMOとは何ですか?」「LLMO対策の具体的な方法は?」といった質問と回答のペアは、AIがユーザーの質問への回答を生成する際にそのまま流用できます。FAQの書き方そのものはインバウンド向けFAQページのSEO設計に整理しています。
ポイントは、見出しに検索意図を反映させることです。「方法について」ではなく「LLMO対策の具体的な5ステップ」のように、見出しだけで内容が把握できるようにします。
条件2:数値データと独自の定量情報
AIが引用する際に最も重視するのが「具体的な数値」です。「多くの企業が導入しています」よりも「調査対象500社のうち73%が導入済み」の方が、AIにとって引用価値が圧倒的に高まります。
ここで重要なのが、CEP(Category Entry Point)フレームワークの考え方です。CEPとは「ユーザーがどんな状況でその情報を必要とするか」を定義するマーケティングフレームワークで、もとはB. シャープ/エーレンバーグ=バス研究所が提唱したブランド成長モデルの中核概念です。
たとえば「海外SEO 費用」で検索するユーザーのCEPは「予算策定段階」です。このユーザーに対して支援実績に基づく費用レンジや、自社の事例ベースのROIデータといった一次情報を提示できれば、AIは具体的な数値を伴うソースを優先的に引用しやすくなります。独自調査や一次データは、他社のコンテンツにはない「引用される理由」そのものです。
条件3:独自見解と「なぜなら」の論理構造
AIが最大公約数的な一般論を生成することは容易です。逆に言えば、どこにでも書いてある情報を、わざわざAIが特定のサイトから引用する理由はありません。AIに引用されるためには、独自の見解(Original Insight)が不可欠です。
ここで活用すべきがRTB(Reason To Believe = なぜなら〜だから)の構造です。単に主張を述べるだけでなく、「なぜそう言えるのか」の根拠を明示することで、AIにとっての引用価値が生まれます。
たとえば「多言語SEOではhreflangタグの設定が最も重要」という一般論を書くだけでは不十分です。「多言語SEOの施策をhreflang設定・コンテンツローカライズ・技術SEOの3軸で優先度を比較すると、hreflangタグの設定ミスが検索流入の低下に直結するケースが多い。その理由は、Googleのクローラーが言語・地域の対応関係を正しく認識できず、意図しないページがインデックスされるためである」のように、根拠の連鎖を示すことが重要です。多言語SEOの全体像は多言語サイトの国際SEO基礎で整理しています。
条件4:構造化データとの連携
コンテンツの「書き方」と同時に効くのが、構造化データ(Schema.org)との連携です。AIモデルの多くはWebクローリング時に構造化データを参照しており、適切にマークアップされたページは情報の正確性が高いと判断されます。
引用元:https://schema.org/Article Schema.org公式のArticle型仕様ページ。記事の本文・セクション・著者・見出しなどをAIに正確に伝えるためのプロパティが定義されている
記事コンテンツに有効な構造化データの種類は、主に以下の3つです。
まずArticle schemaです。著者名・公開日・更新日を明示することで、E-E-A-Tの「経験」と「権威性」をAIに伝達できます。次にFAQPage schemaです。FAQ形式のコンテンツにマークアップすることで、AIが質問と回答のペアを正確に抽出できます。最後にHowTo schemaです。手順形式のコンテンツに対して、ステップごとの情報を構造的に伝達できます。
これらの構造化データは、llms.txtのようなAI向けメタファイルと組み合わせることで効果が最大化します。llms.txtでサイト全体の概要をAIに伝え、個別ページの構造化データで詳細情報を補完する二層構造が理想です。
条件5:KBF(Key Buying Factor)に基づく差別化ポイントの明示
LLMO対策で見落とされがちなのが、KBF(購入決定要因)の明確化です。KBFとは「ユーザーが比較検討する際に重視する決定打」のことで、コンテンツ内でこれを明示することは、AIがブランドを推奨する根拠になります。
AIユーザーが「海外SEO おすすめ 会社」と質問した場合、AIは各社の特徴を比較して回答を生成します。このとき、自社サイトに「どんな基準で選ぶべきか」と「なぜ自社がその基準を満たすか」が明確に書かれていれば、AIはその情報を引用しやすくなります。
たとえば「ネイティブチェック体制の有無」「技術SEOの対応範囲」「多言語対応の実績数」といったKBFを定義し、それぞれについてRTB(裏付け)を添えて記載する。こうすることで、AIが「このエージェンシーを推奨する理由」を構築できるようになります。
AI検索で引用される記事 vs されない記事:実践的な比較
それでは、AI検索で引用されやすい記事とそうでない記事の違いについて解説します。
引用されにくい記事の特徴
AI検索で引用されにくい記事には共通パターンがあります。
まず「まとめ系記事」で内容が浅いケース。「LLMO対策の方法10選」のようなタイトルで、各項目が2〜3行の説明しかない記事は、AIにとって引用する価値がありません。一般的な知識の羅列はAI自身が生成できるため、わざわざ特定のソースを引用する理由がないからです。
次に「主語がない主張」です。「効果が高いと言われています」「多くの企業が採用しています」のような曖昧な表現は、AIが引用する際に「誰が言っているのか」「どの調査に基づくのか」が不明確なため、信頼性が低いと判断されます。
そして「更新されていない情報」です。公開日が古く、最終更新日も記載されていない記事は、AIが「現在も有効な情報か」を判断できず、引用を避ける傾向があります。
引用される記事の共通パターン
一方、AIに引用される記事には「情報の密度」と「論理の一貫性」があります。
具体的には、独自の調査データや事例に基づく主張があること。見出しがユーザーの質問に直接対応していること。主張→根拠→具体例の3層構造で情報が整理されていること。そして定期的に更新され、最終更新日が明示されていることです。
これはGoogleのE-E-A-Tが求める品質基準とほぼ重なります。LLMO対策ではさらに「AIが情報を抽出しやすい構造」が加わります。人間の読者とAIの両方にとってわかりやすい記事を設計することが、これからのコンテンツ戦略の核です。
LLMO対策コンテンツの設計プロセス
ステップ1:CEPの洗い出し
コンテンツ設計の第一歩は、ターゲットユーザーのCEP(Category Entry Point)を洗い出すことです。CEPとは「ユーザーがどんな状況やきっかけで検索(プロンプト入力)するか」を定義するものです。
洗い出しの方法として効果的なのは、過去の問い合わせメールや商談ログを見返すことです。「何に困って相談に来たか?」を整理すると、実態に即したCEPが見えてきます。机上の空論ではなく、実際の顧客の声からCEPを定義することが重要です。海外向けにキーワードを設計する具体的な手順はインバウンドSEOのキーワード調査とローカライズのコツで詳しく解説しています。
ステップ2:KBF/RTBの定義
CEPが決まったら、各シチュエーションに対する「選ばれる理由(KBF)」と「その裏付け(RTB)」を定義します。
| 要素 | 定義 | コンテンツへの反映例 |
|---|---|---|
| CEP | いつ思い出すか | 「英語サイトのアクセスが伸びない時」 |
| KBF | 何で選ぶか | 「ネイティブの検索意図を理解したSEO」 |
| RTB | なぜ信じられるか | 「多言語SEO対応50サイト以上の実績」 |
この3要素を記事に自然に織り込むことで、AIがブランドを「特定の課題に対する解決策」として認識し、推奨する根拠を持てるようになります。海外市場向けSEOで押さえるべきKBF候補は海外市場のSEOで押さえるべきポイントに整理しています。
ステップ3:AIフレンドリーな記事構成の設計
CEP/KBF/RTBが定義できたら、それを記事構成に落とし込みます。AIに引用されやすい構成のポイントは以下の3点です。
まず冒頭200文字に結論を書くこと。AIは記事全体を処理しますが、冒頭の情報を重視する傾向があります。「結局何が言いたいのか」を最初に明示します。
次に各セクションを「質問 → 回答」形式に近づけること。見出しをユーザーの疑問形にし、本文でその回答を提示する構造は、AIの質問応答タスクと親和性が高くなります。
そして数値・固有名詞・具体例を豊富に含めること。抽象的な表現を避け、検証可能な情報を盛り込むことで、AIにとっての引用価値が高まります。
ステップ4:構造化データの実装
記事を公開する際は、適切な構造化データを実装します。最低限必要なのはArticle schemaで、著者情報・公開日・更新日を明示します。FAQセクションがある場合はFAQPage schema、手順解説がある場合はHowTo schemaも追加します。
引用元:https://search.google.com/test/rich-results
Googleリッチリザルトテストでは実装した構造化データがGoogle検索のリッチリザルトに対応しているかを公開URLまたはコード貼り付けで検証できます。
技術的な実装とコンテンツの質を両輪で回すことが、LLMO対策の本質です。
まとめ
LLMO対策は、技術的な設定(llms.txtや構造化データ)とコンテンツ設計の両方が揃って初めて効果を発揮します。
結局のところ、AIに引用されるかどうかは、見出しの作り方とコンテンツの密度で決まります。論理的に整理された見出しとFAQ形式はAIが回答を組み立てる際の足場になりますし、自社調査の数値や固有名詞といった一次情報は、それ自体が「引用される理由」になります。さらに、ユーザーが検索する状況(CEP)と選ばれる基準(KBF)、その裏付け(RTB)の3層を意識した構成にできれば、AIは自社コンテンツを「特定の課題に対する解決策」として認識しやすくなります。仕上げにArticle・FAQPage・HowToのSchema.orgマークアップでAIへの情報伝達を補強し、最終更新日を明示して鮮度を保てば、長期的に引用され続けるコンテンツ基盤ができあがります。
AI検索の普及は「脅威」ではなく「機会」です。適切なLLMO対策を施したコンテンツは、従来のSEOでも高評価を得る良質なコンテンツそのものです。海外向けの全体戦略の中で位置づけたい場合は、海外向けコンテンツマーケティングの全体像を地図代わりに使うと、LLMO施策の優先度が決めやすくなります。
LLMO対策・AI引用最適化ならIGNITEにご相談ください
ここまで解説してきた見出し設計・一次データの提供・CEP/KBF/RTBフレームワーク・Schema.org連携・更新運用は、いずれか一つでも欠けると引用獲得という成果に届きません。「自社の記事がChatGPTやPerplexityで引用されない」「AI Overviewsに表示される条件を整理したい」「LLMO・AEO・AIOの違いを踏まえて何から手をつけるべきか分からない」といったお悩みがあれば、ぜひIGNITEへご相談ください。
IGNITEは、SEOとLLMOを切り分けず、AI検索を含むあらゆる検索動線で「引用される情報源になる」ための設計をワンストップで支援しています。AI検索対策(AEO/AIO/LLMO)サービスでは、ChatGPT・Perplexity・AI Overviewsでの引用獲得状況の診断から、CEP/KBF/RTBに基づくコンテンツ設計、Schema.org構造化データの実装、llms.txtの整備まで一気通貫で対応します。
日本市場と英語圏マーケットの両軸で支援してきた知見をベースに、海外ユーザーへの引用最適化や多言語コンテンツのLLMO設計にも対応可能です。「まず自社の現状を知りたい」という方には無料診断もご用意していますので、お気軽にお問い合わせください。
更新ポリシー
比較記事や施策解説は検索環境やツール仕様の変化に応じて更新されます。実務で利用する際は公開日・更新日・本文中の前提条件を確認してください。
FAQ
この記事に関するよくある質問
この記事はどのような読者向けですか?
AI対策に関心があり、実務で使える判断材料や施策の優先順位を知りたい方向けです。
この記事の内容はいつ確認すべきですか?
比較記事や施策記事は更新日を確認したうえで参照してください。現在の更新日は 2026年5月14日 です。
関連するサービスはありますか?
記事の末尾や関連記事から次に読むべきページへ進めます。具体的な施策相談はお問い合わせページをご利用ください。





